

The European Union has been on a regulatory spree in the digital space, affecting a wide range of Information and Communication Technologies (ICTs), including the previously less regulated area of Open Source software. Key regulations such as the Cyber Resilience Act (CRA), the Artificial Intelligence Act (AI Act) and the Product Liability Directive have begun to reshape the framework within which Open Source software stakeholders operate. In addition, the General Data Protection Regulation (GDPR) and the Copyright in the Digital Single Market Directive continue to have a profound impact on the licensing, development and distribution of Open Source projects.

Cyber Resilience Act (CRA) and Open Source
Context : The regulatory approach of the European Union’s internal market has evolved through various legislative measures, including the NIS Directive (2016), the Cybersecurity Act (2019), and NIS 2 (2022). This progression culminates in the Cyber Resilience Act (CRA), which aims to strengthen the security of digital products for the benefit of all consumers and businesses across the European Union by introducing new cybersecurity requirements for hardware and software products throughout their lifecycle. Published on November 20th, 2024, the CRA grants economic stakeholders 24 to 36 months, until December 11th, 2027, to adapt to its requirements after its entry into force.
In order to better understand the CRA, the CNLL, in partnership with inno³, produced a guide that popularize the legal EU text. The goal of this guide is to clarify the relationship between the CRA and the practices of the Open Source commercial entities.
Access to the guide (in French and in English) : https://code.inno3.eu/ouvert/guide-cra
Access to the slides of the session : https://eolevent.eu/cra-and-open-source/
What does the CRA applies to?
The CRA applies to product with digital elements which is made available on the market or which the intended or reasonably foreseeable use of which involves a direct or indirect connection, whether direct or indirect, logical or physical, to a device or network. Note that this is limited to the version’s product used in a commercial activity.
That means that is excluded: the absence of commercial activity (distribution not for profit, funding provided by donations or grants, no associated paid services, research).
Who is subject to the CRA?
To help you understand if you are subject to the CRA, it mentions 5 roles that have specific obligations and so on sanctions associated.
- Manufacturer
- Open Source steward
- Authorised representative
- Importer
- Distributor
If you want to know which role is made for you, you can look at the following figure.

What are the main obligations of the CRA?
If you want to know which obligations you have to comply, you can look at the following figure.
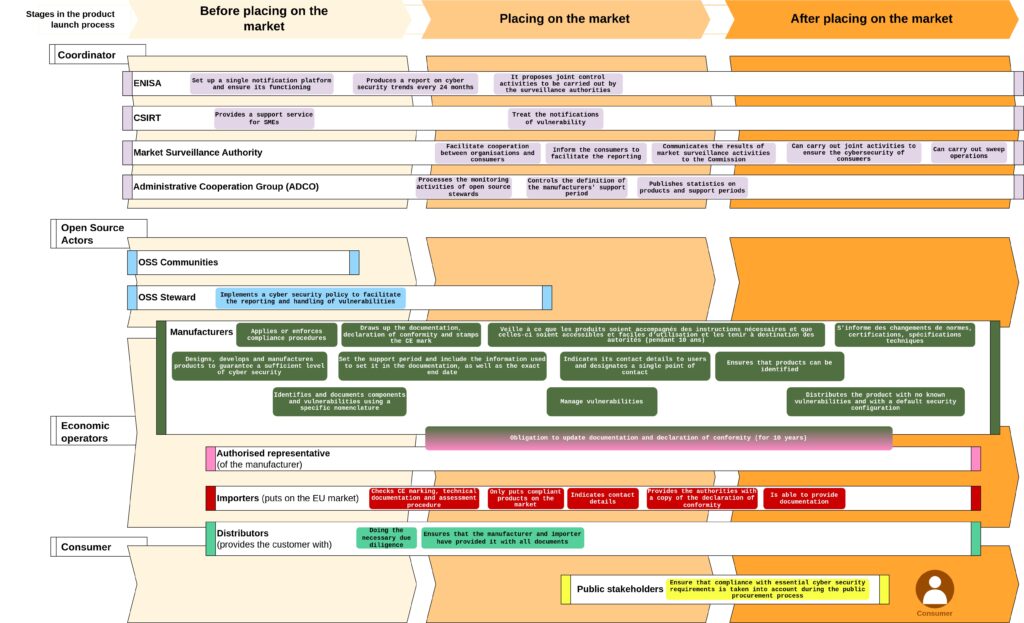
Who will monitor compliance and what will be the sanctions?
The CRA establishes a coordinated regulatory framework, including market surveillance authorities, ENISA, ADCO, and CSIRTs. Sanctions for non-compliance vary by the severity of the breach, with fines up to €15 million or 2.5% of annual turnover for manufacturers.
How can compliance be facilitated and organised for Open Source communities?
Technical documentation is a key compliance tool, requiring a general product description, design and manufacturing details, cybersecurity risk assessments, support period information, standards and certifications, compliance test reports, EU declarations of conformity, and SBOMs (Software Bill of Materials).
The CRA promotes best practices from the Open Source ecosystem, mandating SBOMs that are standardized, qualitative, and exhaustive. SBOMs must detail software components, document vulnerabilities, and be accessible to users and regulators upon request. However, the CRA only focuses on first-level dependencies, while best practices advocate for deeper coverage.
The CRA also envisions voluntary security attestation programs to enhance security practices, accessible to developers, users, and public administrations. It encourages leveraging Open Source methodologies to improve security across the digital ecosystem.
What are the implications of the CRA for public administrations? Is there a specific need to comply? How can a public administration comply?
Public authorities (in the European sense of the term, i.e. all public actors) will also play an active role in strengthening this framework, as Article 5(2) of the CRA stipulates that “where products with digital elements that fall within the scope of this Regulation are procured, Member States shall ensure that compliance with the essential cybersecurity requirements set out in Annex I to this Regulation, including the manufacturers’ ability to handle vulnerabilities effectively, are taken into consideration in the procurement process”.
A key challenge lies in determining who is responsible for analysing compliance, as verifying these requirements—such as quality, licensing, and accessibility—can be complex. This underscores the need for a formal procedure to conduct such checks effectively. The issue also highlights a competency gap specific to public administration, which may lack the expertise required for thorough compliance verification.
How to characterise or define “commercial use” for Open Source projects? Is there a specific process needed to facilitate this characterisation?
Characterizing commercial intent is challenging, as some products are inevitably used by others for commercial purposes. Open Source projects often face significant uncertainties, making it difficult to ensure a stable framework for their development.
Fossology and Scancode, alongside package managers and repositories validated by communities, are valuable tools for managing Open Source compliance. However, many lawyers remain cautious about publishing potentially inaccurate information.
In Italy, a law was established to create dedicated cybersecurity offices for public administration, ensuring software compliance “by design” from the outset. This aligns with EU directives like NIS, which facilitate a shared knowledge base to address such issues.
Of all the issues, what are the challenges of cyber compliance?
Firstly, key concerns include vulnerability management and its relation to compliance, as well as validating licences and determining whether a project qualifies as valid OS. Identifying and managing packages is complex, especially when multiple versions (e.g., patched vs. unpatched) coexist within a project. A centralized and robust validation process, rather than multiple steps, could simplify the process and provide clarity, but it could increase compliance costs.
To do so, foundations such as Eclipse, government or organizations like the EU Commission could play a role in fostering a trustworthy environment and providing guidance on managing packages and compliance.
In this context, knowing that compliance issues are already being raised, how can sustainability be made easier?
To ensure sustainability, companies should upstream solutions, contributing resources and support to maintain OS projects. This would not only address immediate problems but also streamline processes and bolster long-term sustainability.
Key points :
Open Source projects face challenges in integrating fixes resulting from their use, often due to time constraints or lack of structured processes. The Cyber Resilience Act (CRA) could enhance project sustainability by addressing these gaps and promoting better organization.
- Fixing Vulnerabilities: When vulnerabilities are discovered, they must be addressed promptly and made publicly available to maintain the integrity of OS practices. Fixing issues only for private use risks undermining the collaborative nature of OS.
- Support and Processes: The CRA could provide funding and guidance to help OS projects establish processes for efficiently managing vulnerabilities and ensuring fixes are shared widely.
- Preserving OS Principles: To uphold OS values, systems must ensure that solutions benefit the entire community rather than being siloed. This collective approach is critical for maintaining trust and collaboration in OS development.
AI Act and Open Source
Context : The AI Act provides for exceptions applicable to “free and Open Source”. Sounds like good news. But what does “free and Open Source” mean and what does the AI Act apply to? The news over the past weeks leaves a sense of uncertainty about the meaning of “free and Open Source AI system”.
Here you can have a look at the slides for this session:
- Marco Ciurcina – Free and open source exceptions in AI Act
- Laura Garbati – Artificial Intelligence & OS : AI and transparency in Public Administrations
- Carlo Piana – The Open Source AI Definition

How do Open Source communities define artificial intelligence (AI)?
To do so, OSI (Open Source Initiative) worked on a definition that tries to be as complete as possible for Open Source communities. Open Source is fundamentally about fostering freedom. It represents a philosophical approach aimed at enabling frictionless, permissionless innovation. The “four freedoms”—freedom to access the source code, freedom to use it, and freedom to modify and distribute it—are central. Open Source, in this sense, acts as a synecdoche for this broader vision of freedom in software development.
For OSI, AI models do not have “source code” in the traditional sense. Yet the term “Open Source” as applied to AI systems and models has sense. First, it conveys a set of principles that are in common with the software counterparts. Second, because some models started labelling themselves “open source”, while failing to align with the principles of Open Source, therefore clarity needed to be established.
For example, Meta’s Llama imposes field-of-use or business model restrictions, which are contrary to the essence of Open Source.
In the field of AI, the concept of Open Source differs from that of software. It is therefore necessary for the OSI to provide a set of definitions applicable to AI. The project commenced with an in-depth exploration of AI. The plan was to establish a process for gathering consensus, after which the collaborative process itself could commence. The primary challenge during the discussions was the training data set, which is not a core component of AI-related work and use. The process of defining Open Source AI was lengthy and challenging, requiring significant investment in terms of time and resources.
Access to OSI definition : https://opensource.org/ai
They have received numerous endorsements from prominent organisations, including Eleuther Ai and LLM360. Other notable supporters include Software Heritage, Eclipse, and Mozilla.
Otherwise, you can also read Free Software Foundation blogpost on the same subject : https://www.fsf.org/news/fsf-is-working-on-freedom-in-machine-learning-applications
The discrepancy between the positions of the OSI and the Free Software Foundation is an opportunity to initiate a discussion that will continue for some time and ultimately lead to positive outcomes.
How Open Source fits into the AI Act?
The AI Act has a risk based approach (not acceptable risks, systematic risks, high risk, general purpose AI models, Transparency risk, Law risk).
The AI Act does not apply to AI systems released under free and open-source licences, unless they are placed on the market or put into service as high-risk AI systems or as an AI system that falls under Article 5 [prohibited practices] or 50 [Certain AI systems, like chatbots and deep fakes] (art 2.12).
There are other exclusion / exception that apply to the providers of general-purpose AI models (Article 2§12 does not apply to them):
- Exception 1 (Article 25§4): exception for third parties making accessible to the public tools, services, processes, or components, other than general-purpose AI models, under a free and open-source licence. More details are provided in Recital 89 / Recital 102 / Recital 103;
- Exception 2 (Article 53§2): exception to obligations provided by Article 53§1, point (a) and (b);
- Exception 3 (Article 54§6): exception to the obligation to appoint authorised representatives established in the EU.
Recital 104 states that the release of general-purpose AI models under free and open-source licence does not necessarily reveal substantial information on the data set used for the training or fine-tuning of the model. The debate about the need to make available data to comply with the free software definition should not interfere the definition of general-purpose AI models under free and open-source licence.
While we continue to debate about different aspects raised by AI (epistemological problem, oligopolistic risk and scientific developments to come) the issue of free v. open-source AI definition remains open: maybe free software & open source communities, driven by different stakeholders (more scientific community v. more business community) are focusing on different scopes (maximizing possibility to study v. possibility to use).
What principles should AI follow?
As describe in the White Paper on AI, 2019 UE, AI system should follow these principles [that shall be mandatory in the year to come especially for public administrations] :
- Human agency and oversight,
- Technical robustness and safety,
- Privacy and data governance,
- Transparency,
- Diversity, non-discrimination and fairness,
- Societal and environmental,
- Wellbeing,
- Accountability.
What are the problems with AI, particularly in relation to data?
First, the issue is linked to training data. Having access to the training data will be a matter for public administrations, citizens or other stakeholders, and will have a significant impact on the future of the AI ecosystem. Secondly, the issue of reproducibility is also a complex epistemological problem in science, with a number of different definitions. Indeed, reproducibility cannot be envisaged for AI in the same way as for science in general.
Finally, there is an issue with the power around AI systems. Without the input of resources to facilitate the creation of reproducible AI systems, we are at risk of facing a similar oligopolistic situation to that which we are currently experiencing.
In the specific case of public administrations, why is it necessary to create a partnership?
It is essential that public administrations and AI form a strategic alliance, with the objective of achieving mutually beneficial outcomes. It is the responsibility of governments and public administrations to ensure the common good is served. This entails a certain responsibility towards the technology in question. It is imperative that they use it appropriately.
The key issue is not whether public administrations must use AI, but rather how they should manage it. The key question is how we should approach this and in which context. Public administrations must respect the following:
- Equality and respect of constitutional rights (which includes the use of technology, e.g., health);
- Transparency;
- The diligence of the good administrator.
It is imperative that public administrations operate at their optimal level, ensuring justice and equality are upheld. They must demonstrate effective management, provide transparent explanations when necessary, exercise control only to the extent required, and maintain their autonomy. It is not feasible to use all AI systems for every application. It appears that this is a significant solution and a challenge in itself.
The use of AI will work only if it can be combined with a bigger strategy, as a key for a “public oriented” (and controlled) AI. Public administrations have the chance to create an ecosystem completely open with existing laws (Open Data Act, Data Governance Act). They weaponize the ability to big society to preserve sovereignty. That’s why open data and open AI should be always endorsed in public administration.
What tools do you need?
The integration of Artificial Intelligence into public administration requires a similar approach to what is used for the use of software. It is becoming increasingly clear that information technology is no longer just a tool, particularly for public administrations. It is used to ensure the appropriate treatment of citizens, to facilitate autonomy and sovereignty, to guarantee reliability and trustworthiness, to enhance resilience and security, and, of course, to promote transparency. The case of the State of Wisconsin vs Eric L. Loomis is an illustrative example of this.
Is transparent AI the solution ?
Transparency of the algorithms isn’t enough. The systems can be transparent, but they can also remain in a black box It is therefore essential that the transparent AI is effective and that it works in conjunction with other principles. It is not enough for transparency to be merely theoretical; it must also be operational and accessible. This approach not only facilitates explainable AI ex-post but also fosters responsible AI ex-ante. Adherence to standards and models also facilitates the sharing of information, thereby enhancing its visibility and quality. Ultimately, transparency is linked to reuse for standards models, weights and data. In order to reuse, it is essential to have the necessary rights and to be aware of them.
Are there any examples of concrete actions using AI in public administrations?
Italian AI strategy and reuse is an Italian document with three macro directions :
- Methodology to define a protocol for the national to ensure that datasets are trustworthy-by-design and trusthworthy-by-default are legally both engineering and Risk assessment
- Application where the platform will be verticalised on specific areas of application of national interest
- Implementation in order to implement and make provide a platform integrating modern Mlobs and data preparation approach.
Going further? Do research practices need to change in the context of the use of AI?
Today, AI brings complexity (data, algorithms, train, models, hardware…) to validate study, modify or reproduce results and process. It also extends the dependency on development frameworks, external infrastructures, for example to the academic community. Finally, AI is part of scientific processes (even as a “generator” or evaluator of scientific evidence).
This leads to ongoing academic discussions with AI: What is excellent science? Is openness a necessary condition? How can we validate the scientific methods? Which elements of “openness” are shared between science and Open Source communities?
Key points :
The OSI definition will be a key element to help Open Source communities to apprehend the use of AI.
In the public administrations, the use of AI will be most effective when combined with a larger strategy, creating a “public-oriented” (and controlled) AI approach. Public administrations have the opportunity to create an open ecosystem in line with existing legislation, including the Open Data Act and the Data Governance Act. By embracing open data and open AI, public administrations can support society in maintaining its sovereignty. It is therefore essential that open data and open AI are consistently endorsed in public administration.
To ensure effective implementation, public administrations must acquire the necessary competencies to understand the context, identify non-negotiable principles and act accordingly.
This involves:
- asking for full information
- governing data
- preserving accountability
Open Science and Open Source
Context : The European Union and many research organisations are pushing more and more for Open Science in publicly funded projects, something which aligns closely with Open Source principles. Open Science is a wider concept, including open data, content, source and open research collaboration mechanisms, and raises several challenges in tension between regulatory obligations, confidentiality, and open licences.
Here you can have a look at the slides for this session:
- Malcolm Bain – Open Source and Open Science : A happy partnership?
- Ludovica Paseri – Data Regulations, Open Data and Open Science
- Aurelio Ruiz – Issues of open science and licensing from a practical perspective in academic research

What is the context in which Open Science emerged?
The Open Access movement has emerged at the beginning of the 2000s, especially in 2002 with the Budapest declaration. The movement had been carried by new technological tools and the advent of the World Wide Web that created a need for the scientific community to leverage these technologies to foster a more open scientific literature. As defined by Peter Suber in his 2012 book, open access literature must be “digital, online, free of charge and free of most copyright and licensing restrictions”. The objective was to facilitate broader dissemination of scientific research literature. It gives the path to new phenomenon such as open methodology, open notebooks or citizen science and open peer review.
Note that Open Science has been linked to open access (science as a process & science as a common good) and promotes organised scepticism, universalism, communalism, disinterestedness.
Open Science’s objective is to guarantee the free accessibility and usability of scholarly publications, the data resulting from scholarly research, and the methodologies, including code or algorithms, used to generate additional data. The concept of Open Science is evolving, moving beyond the mere concept of Open Access. It is not simply a matter of gaining access to a final paper; it is also about gaining access to the laboratory and to the work in progress. Open is now focusing on sharing and collaboration.
In the specific context of Open Science, what is the definition of openness ?
At European level, the development of Open Science policies is now a crucial point to analyse the Open Science phenomenon. That’s why we can study openness through a classification system to identify the optimal dynamic for Open Science and accommodate all requirements:
- Openness as the democratisation of the access to scientific content: the original idea was to democratise access to the scientific knowledge by disrupting traditional publisher (such as Elsevier, Springer Nature) system with a paywall. In addition, a focus on collaboration between actors (Universities, Publishers, Laboratories, Founding agencies, etc.) rather than blind competition is mandated.
- open science institutionalisation: it answers to demands by the scientific community and by private actors involved in the scientific research process. In addition, the legal framework changed at European level in a complex way resulting in the institutionalisation of Open Science under the principle “As open as possible, as closed as necessary”. This is supported by three principles : principle of sharing (and reuse), of transparency and of integrity. For more information on this specific point, please read Ludovica Paseri article : https://iris.unito.it/handle/2318/1850574
- Openness for pluralism: Today we need a more prescriptive interpretation of open than descriptive. We are currently in a phase of implementation during which we must focus on two principles. First, the one of epistemic equality in order to take into account the conditions under which scientific research carried out. Then, the principle of inclusiveness with the aim of encouraging participation in science by the widest and most diverse range of actors. By fostering a culture of openness, we can accelerate progress in science through collaboration and knowledge sharing.
This tripartition is a reconstruction proposed by the researcher Ludovica Paseri, please read her work for a description of this tripartition : https://iris.unito.it/handle/2318/2018710
What is the data policy for research data in the EU?
A review of the legal framework for scientific research reveals that Open Science is referenced in numerous regulations and is a key component of the EU Data Strategy. The article https://link.springer.com/article/10.1007/s44206-022-00021-3 provides a comprehensive overview of this topic. Additionally, there are numerous specific implementations at the national level. This overview reveals a distinction between incoming data (data collected or created outside of research be reused for the benefit of science) and outgoing data (data produced by the research sector and shared).
- Outcoming data:
- Article 10 of the Directive 2019/1024
- Article 14 of the Regulation 2021/695
- Incoming data:
- The notion of access to data for the benefit of scientific research of the GDPR.
- The notion of data altruism of the DGA
- DSA art 40
- Data Act art 21
The objective of creating scientific policies is to define obligations, incentives and resources in order to achieve the desired goal of openness. The key to success is enactment by researchers and their specific communities (science as a self-regulated environment). Policies for Open Science must align with what is good science for researchers. What is the optimal development framework? What is the best repository?
What are the similarities between Open Science and Open Source? And on the other hand the differences?
There are some similarities between Open Science and Open Source practices :
- Nature: both have a non rival and a non scare approach.
- Objectives: both have the same objectives such as accessibility, reproducibility, reusability, replicability.
On the other hands, there are differences :
| Open Science | Open Source |
| In practices | |
| Publish once, carefully Prior publication peer review Counter paper to refute ideas, results, competitively Repeat? not necessarily | Publish often Publish early Post publication peer review Correct errors, collaboratively Repeat |
| In the search for protection | |
| IPR objective: patent, design, automatic copyright IPR logic for investing in Science: monopoly for exploitation and further investment | Automatic protection by copyright Open Source has do overturn the IPR (copyleft) to make it work for free and Open Source IPR logic for Open Source: ensure attribution and continued openness of the code |
| In motivation | |
| Scientific reputation by publishing Confidentiality until publication (by becoming the first to publish) Patent monopoly protection for licensing opportunities ROI in terms for monetary return and re-investment in R+D Impact measured in citation and monetary in licensing terms. | The technical reputation is linked to the quality of code Publish early, share and improve (and maintain) Impact measured in downloads, use and reuse, contribution to other projects |
| In implementation | |
| The implementation of many sciences requires significant infrastructure (machines, lab, e.g.) | Software implementation is near from zero marginal cost (exception with AI) |
But among all, another major difference is the risk factor. During COVID-19, this issue had been raised for Open Science practices :
- There is a risk of significant reputational damage if the media and the public take findings that have not yet been peer-reviewed at face value.
- While peer review plays a vital role in maintaining the quality, transparency and reproducibility of published articles, it is not a panacea for flawed studies being published and used by the media and health authorities.
- Some of the misuses and abuses highlighted are a direct result of the current metric-centred evaluation of research and researchers, which has already been shown to lead to questionable research practices in the past.
What’s the place of software in the scientific process?
It is becoming increasingly evident that software plays a pivotal role in the scientific process. As scientific research increasingly relies on computer code for simulations, calculations, analysis, visualisations and general data processing, it is vital to ensure access to this code, just as it has traditionally been crucial to demonstrate and derive any new mathematical techniques introduced for analysis. (Marcus Hanwell, opensource.com).
- More and more Open Source is being produced in R+D
- Publications should publish open code and open data “better” (e.g. with a licence)
- Open Source best practices should be (or could be better) implemented in research
- Open collaboration (environments, practices, incentives)
- Licence compliance procedures
- Governance processes
- Community management and sustainability
- Avoid the pitfalls of non-openness:
- “academic non-commercial” licences? (context specific)
- Non (open) data – particularly in ML based research
- Register to get access… / Access Agreements
What inspiration can Open Science borrow from Open Source practices?
- What (Open) Science can learn from Open Source ?
- Strength through openness and freedom
- Licensing establishes the ground rules of the communities
- Community and governance are critical
- Need to
- Change approach to scientific incentives, expectations and reward
- Change assessments of impact of research – stop measuring patents and licensing revenues
- It depends on:
- Differences between basics and applied research
- Differences between digital/non-digital science
Key points :
The Open Source community has provided narratives and solutions (licences) for excellent scientific narratives and practices. Nevertheless, both, Open Science and Open Source are still sharing some key tensions that need to be solved.
- Relevance of external power dynamics that impact the self-regulation of the academic field.
- Influence of big corporations on the academic field
- Reproducibility / replicability at scale – validation process. Scientific method.
- Direct influence (funding, data, talent, capture of open results)
- Indirect influence (narrative generation societal demands research directions, aspirations of newcomers to science)
- Inclusiveness: who can participate in science, what science prioritized
- Disinterest: hindering access to knowledge. Even citizen science is captured (crowds “privately” captured)
- Knowledge production as a collective process: difficulties in the processes of licensing (e.g. attribution) – Open Source community has already provided solutions before.
To proceed with this subject, further questions must be addressed:
- Can public universities and research centres leverage the “politics of data” opportunities?
- Are the appropriate structures and infrastructure in place to ensure compliance?
- What is the current state of openness in scientific research?
- Which assets (results) can be published and shared?
- Which processes may be useful or required for opening and sharing with a community?
- Which community should be involved? Is it the whole world or a more restricted set of privileged partners?